transformer(트랜스포머)가 사용되는 모델의 대표작은 작년 말에 나온 ChatGPT가 있다. 자연어 생성 모델의 대표작인 ChatGPT가 있다면 이미지 모델에선 Vision Tansformer(ViT)가 다양한 모델의 백본(backbone)으로 사용되고 있다. 트랜스포머가 쏘아올린 작은 공은 많은 분야에 큰 반향을 불러왔다. 오늘은 이 transformer를 pytorch 공식 코드를 보며 이해해 보고 빠르게 구현까지 해보자.
Optional
attention
attention 함수를 정의하면 정말 간단하게 나타난다. query Q, key K, value V 3개의 계산이 정말 한 큐에 끝난다. 수식이 간단하기 때문이다.

import numpy as np
import softmax
def attention(K,Q,V, d=1):
tmp = np.matmul(Q, np.transpose(K))
attention = np.matmul(softmax(tmp/np.sqrt(d)), V)
return attentionsoftmax는 옛날에 구현해 놓은 걸 사용해 보겠다.
def softmax(arr):
exps = np.exp(arr)
return exps / np.sum(exps)MultiheadAttention
1. 시작
pytorch의 트랜스포머 모듈 코드 위쪽에는 import 하는 모듈 및 라이브러리들을 확인할 수 있다.
import copy
from typing import Optional, Any, Union, Callable
import torch
from torch import Tensor
from .. import functional as F
from .module import Module
from .activation import MultiheadAttention
from .container import ModuleList
from ..init import xavier_uniform_
from .dropout import Dropout
from .linear import Linear
from .normalization import LayerNorm
이중에서 .activation에서 import 하는 MultiheadAttention을 살펴보자. 해당 클래스의 전체 코드는 아래 링크와 같다.
https://pytorch.org/docs/stable/_modules/torch/nn/modules/activation.html#MultiheadAttention
torch.nn.modules.activation — PyTorch 2.0 documentation
Shortcuts
pytorch.org
클래스의 주석을 확인해 보면 아래와 같이 transformer의 기본적인 로직을 확인할 수 있다.

이때 Q는 query, K는 key, V는 value를 의미한다. MultiHead(Q, K, V)는 어텐션을 거친 결과인 head들을 concat 해서 가중치 계산을 한 결과임을 알 수 있다.
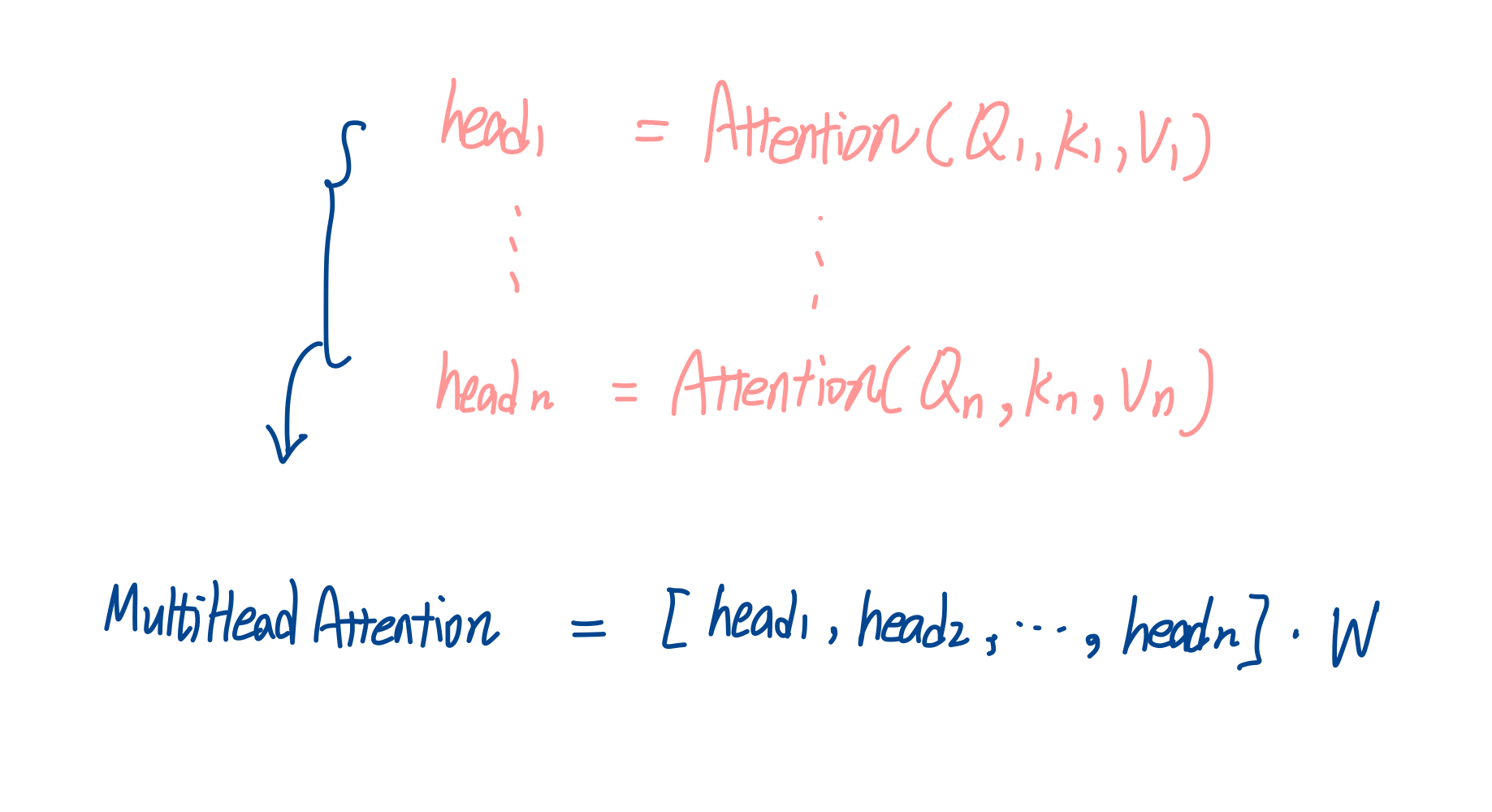
2. def __init__
이제 MultiHeadAttention 클래스의 init 함수를 살펴보자. 아래와 같이 embedding 차원(embed_dim), head의 수(num_heads)를 필수로 받고 있음을 알 수 있다.
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False,
kdim=None, vdim=None, batch_first=False, device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
MultiHeadAttention 클래스에서 반환하고자 하는 것은 말 그대로 multi head attention의 결과일 것이다. num_heads만큼의 head들을 concat 한 결과를 반환하므로 1개의 head 하나의 임베딩은 embed_dim // num_heads가 된다. 예시로 MultiHeadAttention의 임베딩 차원 수가 128, head 수가 4개라고 가정했을 경우 이때의 head_dim은 128 // 4 == 32가 된다.
self.num_heads = 4 ; self.embed_dim = 128
아, MultiHeadAttention은 head 4개를 concat 해서 128차원짜리 embedding 하나를 반환하겠구나!
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
다음은 가중치 w metrix를 initalize해주는 부분이다. Q, K, V의 dimension이 주어지지 않을 경우는 embed_dim과 같다고 가정한다. Q는 기본적으로 (embed_dim, embed_dim)의 행렬이다.
if not self._qkv_same_embed_dim:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim), **factory_kwargs))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim), **factory_kwargs))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim), **factory_kwargs))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim), **factory_kwargs))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
딥러닝 층은 기본적으로 w*x + b 의 linear layer를 쌓는 형태가 된다.
W는 가중치, b는 bias를 의미한다. 학습이 진행되면서 최적의 w를 찾아가는 것. 참고: 이전 글 - 파이썬과 기초 딥러닝 개념 1
그렇기 때문에 Q, K, V에게도 b_q, b_k, b_v인 편향값이 존재할 수 있다. 이 값들을 정의해 준 코드가 아래 블록에 해당한다. key, value의 bias를 지정해주고 싶다면 따로 self.bias_k, self.bias_v 값을 정해주는 것을 알 수 있다. 하지만 보통의 경우 Q, K, V의 bias는 self.in_proj_bias 행렬로 이용할 수 있다.
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim, **factory_kwargs))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = NonDynamicallyQuantizableLinear(embed_dim, embed_dim, bias=bias, **factory_kwargs)
if add_bias_kv:
self.bias_k = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
self.bias_v = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
else:
self.bias_k = self.bias_v = None
또한 out_proj를 선언해 주는 부분도 있다. MultiHeadAttention 수식에서 head들을 concat해준 후 행렬곱을 진행하는 가중치 W의 위치다.
self.out_proj = NonDynamicallyQuantizableLinear(embed_dim, embed_dim, bias=bias, **factory_kwargs)
전체 init 코드를 그림으로 정리하면 다음과 같다.


3. forward
attention에서 L은 타겟 시퀀스 길이, S는 소스 시퀀스 길이, N은 batch size, E는 임베딩 차원을 의미한다. 예를들어 Q가 (S==16, E==32) 차원의 임베딩이라면 소스 시퀀스 길이가 16이고 임베딩 dim이 32인 벡터를 의미한다.
만약 batch size가 있는 데이터가 들어와 Q(S==16, N==32, E==32)의 벡터가 있다고 가정하자. 이 쿼리 Q는 배치 사이즈가 32이고, 각 배치의 소스 시퀀스 길이는 16, 임베딩 차원은 32인 벡터인 것이다.
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
average_attn_weights: bool = True,
is_causal : bool = False) -> Tuple[Tensor, Optional[Tensor]]:
r"""
.. note::
`batch_first` argument is ignored for unbatched inputs.
"""
is_batched = query.dim() == 3
다음 블록에서는 key와 어텐션의 mask를 정의하고 있다. 이때 _canonical_mask라는 함수를 불러오고 있다. 여기서는 _canonical_mask의 mask args가 그대로 반환된다고 생각하면 된다. 이때 attn_mask와 key_padding_mask는 forward함수의 인자로 받은 상태다. 물론 이 마스크는 없어도 된다. 그렇기 때문에 args에서 None을 default로 주고 있다.
잠시 torch.nn.functional에 정의되어 있는 _canonical_mask를 확인하고 가보자. 가볍게 mask의 type을 확인하고 그대로 mask를 반환하는 단순한 함수다. 만약 mask가 float이 아닐 경우에 -inf으로 채운 새로운 mask를 return 해준다.
def _canonical_mask(
mask: Optional[Tensor],
mask_name: str,
other_type: Optional[DType],
other_name: str,
target_type: DType,
check_other: bool = True,
) -> Optional[Tensor]:
if mask is not None:
_mask_dtype = mask.dtype
_mask_is_float = torch.is_floating_point(mask)
if _mask_dtype != torch.bool and not _mask_is_float:
raise AssertionError(
f"only bool and floating types of {mask_name} are supported")
if check_other and other_type is not None:
if _mask_dtype != other_type:
warnings.warn(
f"Support for mismatched {mask_name} and {other_name} "
"is deprecated. Use same type for both instead."
)
if not _mask_is_float:
mask = (
torch.zeros_like(mask, dtype=target_type)
.masked_fill_(mask, float("-inf"))
)
return mask key_padding_mask = F._canonical_mask(
mask=key_padding_mask,
mask_name="key_padding_mask",
other_type=F._none_or_dtype(attn_mask),
other_name="attn_mask",
target_type=query.dtype
)
attn_mask = F._canonical_mask(
mask=attn_mask,
mask_name="attn_mask",
other_type=None,
other_name="",
target_type=query.dtype,
check_other=False,
)
그러고 여러 선언과 벡터 차원을 맞춰주는 코드들이 있고, 그 후에 다음과 같이 multihead attention을 수행하게 된다. attn_output과 attn_output_weights들을 반환하고 있다. MultiHeadAttention클래스의 forward 함수의 반환값은 어텐션 결과와 더불어 결과 가중치도 같이 반환하는 걸 알 수 있다.
if not self._qkv_same_embed_dim:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask,
use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight,
average_attn_weights=average_attn_weights,
is_causal=is_causal)
else:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask,
need_weights=need_weights,
attn_mask=attn_mask,
average_attn_weights=average_attn_weights,
is_causal=is_causal)
if self.batch_first and is_batched:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights
4. multi_head_attention_forward
torch.nn.functional에 있는 multi_head_attention_forward 함수를 가보면 다음과 같이 정의되어 있는데, 코드를 읽다 보면 multi_head_attention_forward를 오버라이딩하고 있음을 알 수 있다. 그렇다면 진짜 multi_head_attention_forward함수는 어디에 있을까? C++함수로 짜여있다....!
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
embed_dim_to_check: int,
num_heads: int,
in_proj_weight: Optional[Tensor],
in_proj_bias: Optional[Tensor],
bias_k: Optional[Tensor],
bias_v: Optional[Tensor],
add_zero_attn: bool,
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_separate_proj_weight: bool = False,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
static_k: Optional[Tensor] = None,
static_v: Optional[Tensor] = None,
average_attn_weights: bool = True,
is_causal: bool = False,
) -> Tuple[Tensor, Optional[Tensor]]:
tens_ops = (query, key, value, in_proj_weight, in_proj_bias, bias_k, bias_v, out_proj_weight, out_proj_bias)
if has_torch_function(tens_ops):
return handle_torch_function(
multi_head_attention_forward,
구현
그냥 지나가기는 아쉬우니까 파이썬 버전으로 multi_head_attention_forward 함수를 간략하게 짜보자. 오늘 포스팅의 optional에서 짜놓은 attention함수를 활용하고, 편의상 mask는 없다고 가정한다. 위 multi_head_attention_forward의 input args 중 weight, 그리고 out_proj_weight 까지만 받는 새로운 함수를 선언한다.
def multi_head_attention_forward(
query, key, value, embed_dim, num_heads,
in_proj_weight, head_dim):첫 번째 head를 봤을 때 nquery, nkey, nvalue에 가중치를 곱해준다. in_proj_weight의 차원은 (embed_dim*3, embed_dim)이었음을 기억하며 새롭게 가중치 nq_weight, n_k_weight, n_v_weight를 정의해 준다.
#(embed_dim , query_dim or key_dim or value_dim)
q_in_proj_weight = in_proj_weight[:embed_dim, :]
k_in_proj_weight = in_proj_weight[embed_dim : embed_dim*2, :] # n_emb, key_
v_in_proj_weight = in_proj_weight[embed_dim*2 :, :]
#(head_dim, query_dim // n_heads)
n_q_weight = q_in_proj_weight[head_dim*n : head_dim*(n+1), head_dim*n : head_dim*(n+1)]
n_k_weight = k_in_proj_weight[head_dim*n : head_dim*(n+1), head_dim*n : head_dim*(n+1)]
n_v_weight = v_in_proj_weight[head_dim*n : head_dim*(n+1), head_dim*n : head_dim*(n+1)]attention을 수행해 준다.
head = attention(nquery, nkey, nvalue)이걸 head만큼 해줘야 하기 때문에 for문 안에 넣어준다. 이때 기존의 query, key value가 n개로 쪼개졌다. 그래서 위의 nquery, nkey, nvalue가 탄생했다.
nquery = np.matmul(nquery, np.transpose(n_q_weight))
nkey = np.matmul(nkey, np.transpose(n_k_weight))
nvalue = np.matmul(nvalue, np.transpose(n_v_weight))
head = attention(nquery, nkey, nvalue)이제 head들을 합쳐주고 가중치를 곱해주면 된다.
if n == 0:
heads = head
else:
heads = np.concatenate([heads, head], axis=1)
print(n)
heads = np.array(heads)
print(heads.shape)
multiheadatt = np.matmul(heads, out_proj_weight)끝! 코드를 실행해 보자.
import numpy as np
S = 40 #sequence length
E = 64 #query embedding shape == embed_dim
embed_dim = 64
num_heads = 8
head_dim = embed_dim // num_heads
in_proj_weight = np.random.randn(3 * embed_dim, embed_dim)
in_proj_bias = np.random.randn(3 * embed_dim)
out_proj_weight = np.random.randn(embed_dim, embed_dim)
query = np.random.rand(S,E)
key = query
value = query
def multi_head_attention_forward(
query, key, value, embed_dim, num_heads,
in_proj_weight, head_dim, out_proj_weight):
heads = []
for n in range(num_heads):
nquery = query[:,head_dim*n : head_dim*(n+1)]
nkey = key[:, head_dim*n : head_dim*(n+1)]
nvalue = value[:, head_dim*n : head_dim*(n+1)]
#(embed_dim , query_dim or key_dim or value_dim)
q_in_proj_weight = in_proj_weight[:embed_dim, :]
k_in_proj_weight = in_proj_weight[embed_dim : embed_dim*2, :] # n_emb, key_
v_in_proj_weight = in_proj_weight[embed_dim*2 :, :]
#(head_dim, query_dim // n_heads)
n_q_weight = q_in_proj_weight[head_dim*n : head_dim*(n+1), head_dim*n : head_dim*(n+1)]
n_k_weight = k_in_proj_weight[head_dim*n : head_dim*(n+1), head_dim*n : head_dim*(n+1)]
n_v_weight = v_in_proj_weight[head_dim*n : head_dim*(n+1), head_dim*n : head_dim*(n+1)]
print(n_q_weight.shape)
nquery = np.matmul(nquery, np.transpose(n_q_weight))
nkey = np.matmul(nkey, np.transpose(n_k_weight))
nvalue = np.matmul(nvalue, np.transpose(n_v_weight))
head = attention(nquery, nkey, nvalue)
if n == 0:
heads = head
else:
heads = np.concatenate([heads, head], axis=1)
print(n)
heads = np.array(heads)
print(heads.shape)
multiheadatt = np.matmul(heads, out_proj_weight)
return multiheadatt
multi_head_attention_forward( query, key, value, embed_dim, num_heads,
in_proj_weight, head_dim, out_proj_weight).shape잘된다. multi_head_attention_forward 의 output shape이 (40,64) 즉 (S, E)로 예쁘게 잘 나왔다.
오늘은 pytorch 코드를 뜯어보기로 간단하게 글을 작성하려 했는데 어쩌다 보니 MultiHeadAttention까지 구현하게 됐다. Key, Value가 Query와 dim이 다를 경우 조금 복잡해질 거 같았다. 공식 pytorch code에서 weight 들의 dim을 key, query, value 3개 다 합쳐서 하나의 텐서(in_proj_weights)로 받는 것을 보니 c++ 코드에서는 (k, q, v) * in_proj_w으로 한방에 처리할 것 같다. 디테일을 볼 수 있어서 좋았던 시간이었다. 이 글을 보는 사람들도 multi head attention의 내부 구현 이해에 도움이 되었기를 바란다.
참고 : https://pytorch.org/docs/stable/_modules/torch/nn/modules/transformer.html#Transformer
torch.nn.modules.transformer — PyTorch 2.0 documentation
Shortcuts
pytorch.org
'머신러닝 > 파이썬 구현 머신러닝' 카테고리의 다른 글
| Multi Armed Bandit 의 Epsilon Greedy, Tompson Sampling 파이썬으로 구현하기 (2) | 2025.10.06 |
|---|---|
| 파이썬 구현으로 알아보는 TF-IDF와 BM25 (0) | 2025.09.13 |
| 딥러닝 이론 optimizer 정리 - GD , SGD, Momentum, Adam (0) | 2022.05.14 |
| 파이썬으로 기초 CNN 구현하기 1 - conv, pooling layer (4) | 2022.04.17 |
| 파이썬과 기초 딥러닝 개념- 이론편 1 (0) | 2022.04.03 |