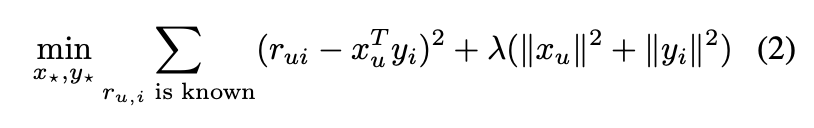오늘은 지난 포스트 Matrix Factorization(MF)와 ALS에 이어서 Factorization Machine(FM)에 대한 기초를 다뤄볼 예정이다.
MF의 핵심은 user 와 item 간 interaction에 대한 하나의 행렬 A이 있을 때, 이를 user 벡터 U와 item 벡터 V로 행렬분해를 한 형태로 가져갈 수 있다. U와 V의 dot product가 user-item 간 유사도를 나타내는 것으로 이해할 수 있었다.
FM도 하고자 하는 바는 유사하다. user들과 item 이 주어졌을 때 user에게 무슨 아이템을 추천해야하는지를 알고 싶다. 하지만 비슷한 이름에 비해 과정은 사뭇 다르다.
- 참고 paper : Factorization Machines. 2010
1. PREDICTION UNDER SPARSITY
FM은 ranking을 예측하는 regression 문제로 접근하지 않고 classification task로 풀고자 한다. user-item-score 쌍이 anti symmetric이라 postive sample로만 학습한다. (참고: item a가 b보다 항상 ranking이 높다면 b가 a보다 높을 일은 없다.)
FM도 highly sparse data를 가정한다. figure1을 보면 user와 item feature를 concat해 하나의 feature로 활용한다. 이는 오직 user-item interactioin을 value로 표현했던 MF와는 다르다.
fig1의 x(1) feature를 예시로 설명하면, A user가 TI 영화를 봤고, 지금까지 영화들에는 다음과 같은 평점을 주었으며, TI 영화는 13개월차에 봤고(논문에선 2009년부터 1개월씩 +1 카운트한다), 직전에 A가 평점메긴 영화들에는 무엇이 있었는지를 나타낸다. target y(1)은 A user가 TI item에 준 rate다. 5라고 되어있으니 5점이다.
여러 피쳐들을 활용해서 ranking 예측 모델을 설계하고 있음을 알 수 있다.

2. FACTORIZATION MACHINES (FM)
FM에선 degree d = 2 로 설정해 dot product한다. feature x1, x2가 있다고 가정했을 때 이 둘을 dot product 함으로써 두 피쳐간의 인터렉션을 활용하는 것이다. 아래 Equation에서의 마지막 항에 해당한다. v는 따라서 x_i와 x_j의 인터렉션에 대한 weight가 된다. w0은 global bias (~= b), w_i는 feature weight를 의미한다. 수식 생김새를 보면 알듯이 gradient descent(GD)를 쓸 수 있다.
( 수식 내 x는 위 fig1와 다르다! )

v는 자체로 k개의 factor를 가지고 있다. 만약 k가 충분히 크다면 어떤 interaction 행렬 W에 대해 W = V trans(V) 가 성립되는 V를 찾을 수 있다. 이러면 모든 피쳐들간의 상호작용을 V의 dot product로 나타낼 수 있게 될 수 있다. 하지만 인터렉션 자체가 sparse하기 때문에 고차원으로 나타내지 않고 k를 작게 해서 표현한다.

그런데 metrix자체가 sparse하지 않았던가. x_i, x_j간 인터렉션을 잘 나타낼 수 있을까? 논문에선 이 문제를 factorization으로 해결한다.
user A가 item ST에 대해 인터렉션한 적이 없다고 해보자. <v_A, v_ST> = 0 일까? 다른 유저들 B, C를 보니 item ST, SW을 둘다 본 적이 있다. 여기서 v_ST와 v_SW가 유사할 수 있다는 것을 캐치한다. 그래서 <v_A , v_ST> ~= <v_A, v_SW>로 근사할 수 있다.
그럼 이거 연산량은 괜찮을까? 직관적으로 보면 O(n**2) 일 것 같지만 실제 식을 풀어보면 다행히 O(k n)이다.

이후 이 식을 regression, classification, ranking 등에서 쓸 때는 오버피팅 방지를 위해 R2 reg를 추가한다.
Matrix and Tensor Factorization
MF은 FM의 피쳐를 x 하나만 썼을 때의 특이 케이스로 해석할수도 있다. fig1 에서 피쳐가 user, item 2가지만 있다고 가정하면 FM 수식이 다음과 같게 된다.

이는 Matrix Factorization에서는 dot(u, v)를 구하는데, 이를 행렬이 아닌 스칼라 계산식으로 생각하면 위와 유사하게 된다.
'논문리뷰' 카테고리의 다른 글
| [추천 ML paper] 16년도 유튜브 recommendation system 논문 리뷰 (0) | 2025.10.26 |
|---|---|
| [추천 ML paper] 16년도 구글 Wide&Deep 논문 리뷰 (0) | 2025.10.19 |
| [논문 리뷰] stable diffusion paper 뜯어보기 (0) | 2025.09.27 |
| [paper] Meta Imagine Flash 논문 리뷰 (0) | 2024.06.06 |
| [Paper] DPO 논문 리뷰 (1) | 2023.11.13 |