오늘 가져온 논문은 Deep Neural Networks for YouTube Recommendations 이다. 유튜브에서 2016년도에 낸 추천 알고리즘에 대한 내용이다.
이 논문을 비롯한 여러 추천 시스템이 2 stage 양상을 띈다.
저번에 다룬 구글의 wide&deep과도 유사한 점이 많다. 그럼 시작!
1. Introduction
딥러닝을 이용해서 추천하고싶어! 그러면서 풀고자 한 문제는 크게 세가지다.
- Scale: 당시 16년도의 많은 추천 알고리즘들은 작은 스케일에선 괜찮은 효과를 내지만 유튜브같은 방대한 풀과 유저에서는 효과를 못봤다고 한다.
- Freshness: 신규 업로드되는 유튜브 컨텐츠가 많기 때문에 최신성 유지와의 balance를 고려해야 한다. 추천에서의 exploration / exploitation 균형과 같다.
- Noise: 컨텐츠의 메타데이터도 퀄리티가 좋지 않고, 유저 인터렉션에도 노이즈가 많다.
당시 유튜브와 구글은 많은 문제를 딥러닝으로 해결하고자 하는 시도가 있었다고 한다. (추천 DL이 거의 전무했던 시기) 그래서 lesson learn에 좀 더 치중한 내용을 다루는 듯 하다.
2. System Overview
전체적인 아키텍처는 다음 figure 2와 같다. 크게 candidate generation과 ranking으로 나눌 수 있다.

1) candidate generation에선 유저가 관심있을법한 컨텐츠들을 여기서 미리 선별한다.
2) ranking 에서 보다 자세한 best recommendation이 이루어진다.
candidate generation에서는 검색 retriever, CF 등 여러 소스를 같이 혼합해서 사용할 수 있다.
3. CANDIDATE GENERATION
유저와 관련된 몇백개 정도의 비디오를 선별하는 단계다. 여기서 DNN extreme multitask classification 문제로 접근한다. 유저 벡터와 아이템(비디오) 임베딩이 input으로 주어질 때, 해당 아이템들 중 가장 볼법한 것을 분류 문제로 만든 것이다. 이때의 학습 라벨은 좋아요같은 explicit feedback이 아닌 시청시간(watches)을 통한 '완시'로 기준을 세웠다. 여기서 하고자 하는 건 기존 추천 시스템의 MF(Matrix Factorization)을 대체하는 것이다. 좋아요 등을 안쓴 이유는 사람들이 많이 안써서(~=sparse해서)라고 한다.
아래 식은 softmax다. U는 유저 벡터, C는 컨텐츠 벡터다. 전형적인 분류 문제로 바뀌었다.

많고 많은 컨텐츠들을 전부 분류모델에 태울 순 없으니 candidate sampling을 한다. 랜덤으로 선택한 negative 컨텐츠들도 학습에 사용하여 오버피팅을 방지한다.
infer시엔 효율을 위해, 즉 시간 단축을 위해 softmax 대신 Nearest Neighbor 탐색, dot product로 후보 컨텐츠들을 선별한다.
컨텐츠 임베딩은 word embedding으로 진행했다. 마찬가지로 유저임베딩에서도 유저가 시청한 컨텐츠들의 임베딩을 concat해서 dense vector를 생성했다. 그래서 figure3의 그려진 최하단 블록은 유저 임베딩을 나타낸 거다.

딥러닝을 MF 대신 사용하면서 이점은 categorical, continuous 피쳐도 모델에 input으로 주기 용이해졌단거다. 유저의 검색이력과 성연령 등등 다양한 피쳐를 input으로 사용한다.
모델 학습시엔 컨텐츠 최신성을 고려하기 위해 비디오의 age도 같이 넣어준다. 컨텐츠가 업로드 후 빠르게 소모되는 패턴을 분석한 결과를 피쳐에 적용했다. 시간이 지날수록 컨텐츠의 인기도도 달라지기 때문에 training window를 도입하고 example age도 같이 넣어 학습한다. 서빙시에는 example_age == 0으로 주는데, 이는 컨텐츠의 가장 최신의 인기패턴을 반영하라는 것과 같다.

추가로 모델이 exploit에 치중되지 않게 CF도 도입하고, 학습 편향이 특정 유저군에 집중되지 않도록 유저 당 학습셋을 고정했다.
추천 피드를 검색 결과만 뜨게 하는 것도 지양할 수 있게 검색어 발생시점 데이터도 사용하지 않는다. 유저가 어느날 테일러 스위프트를 검색했다가 다시 나타났을 때, 테일러 스위프트와 관련된 컨텐츠만을 추천하는 것을 방지하기 위함이다.
그리고 학습 라벨을 고르는 과정은 다음과 같이 이어지는 행동에서 추출한다. 유저의 시청이 플로우가 이어지는 다음 시청이었을 때만 해당 데이터를 정답셋으로 사용한다.
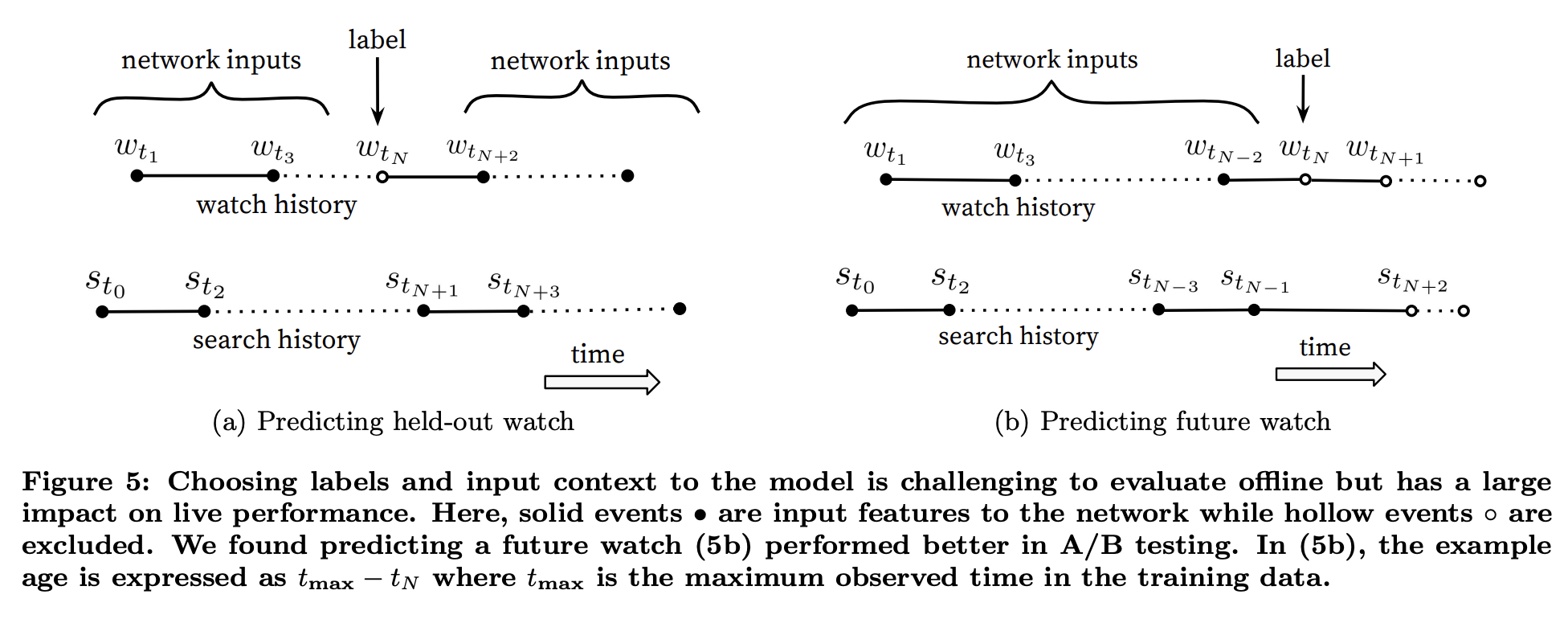
유저 피쳐에선 본것 최근 최대 50개, 검색어 최근 50개를 함께 사용한다.
4. RANKING
candidate generation과 유사하게 DNN 아키텍처를 차용했고 logistic regression으로 문제를 풀었다. 비디오들의 score를 메기는 단계다.
피쳐로는 the traditional taxonomy of categorical and continuous/ordinal features을 사용했다. 특히 유저의 직전 컨텐츠들과의 interaction으로 이뤄졌다. 이 체널 컨텐츠를 얼마나 봤나, 특정 주제에 대한 컨텐츠를 최근 언제 봤나 등등, 그리고 generation에서 얻은 해당 컨텐츠의 점수도 같이 사용한다.
churn(변화) 개념도 있다. 유저가 봤는데 지나친 컨텐츠에 대한 피쳐값을 추가해서, 자연스럽게 랭킹이 낮아질 수 있도록 한다.
정황상 컨텐츠의 ID embedding은 lookup table을 사용했다고 하니 카테고리등의 text 임베딩도 녹였을 것으로 보인다. 이를 categorical 피쳐로 녹인듯하다.
추가로 continuous feature는 normalize해서 사용했다. quantile norm 후 루트를 씌웠다.
아래 fig에서의 language embedding은, 자연어 language를 뜻하진 않아보인다. user language도 유저벡터를 의미하는 것으로 보인다.

모델은 (당연해보이지만) hidden layer를 더 둘수록 성능이 좋았다고 한다.
5. CONCLUSIONS
AB 테스트에서 시청시간 지표가 개선됐다고 한다. 얼마나 개선됐는지 표는 없다.
'논문리뷰' 카테고리의 다른 글
| [추천 ML paper] 추천시스템 Factorization Machine(FM) 완벽 기초 (0) | 2025.11.09 |
|---|---|
| [추천 ML paper] 16년도 구글 Wide&Deep 논문 리뷰 (0) | 2025.10.19 |
| [논문 리뷰] stable diffusion paper 뜯어보기 (0) | 2025.09.27 |
| [paper] Meta Imagine Flash 논문 리뷰 (0) | 2024.06.06 |
| [Paper] DPO 논문 리뷰 (1) | 2023.11.13 |