거의 1~2년에 한번씩은 spark를 사용하는 프로젝트가 생긴다. spark3이 된 후로 Pyspark를 많이 써서, Scala Spark는 주로 사용하지 않는 편이다. 스파크를 가끔씩 사용하다 보니 할 때마다 헷갈려서 개념을 다시 찾아보곤 한다. 오늘은 그런 개념들을 한번에 정리해놓고자 한다. spark client와 cluster mode의 차이를 정리해보겠다.
0. 선수 지식
스파크 어플리케이션은 크게 spark Driver와 Executor, 그리고 Cluster Manager(CM)으로 나눌 수 있다.

Driver Process
위 fig에서 보이는바와 같이, spark 앱을 실행하고 제어하는 역할를 한다. cluster manager와 통신도 담당한다.
SparkSession
application마다 하나의 세션이 존재한다. 스파크 잡을 실행시키면 driver process에 있는 spark session이 executor에게 명령을 내린다. 즉, executor를 실행한다.
Executor
task를 실행시키고 task상태를 전달한다.
Cluster Manager
말 그대로 클러스터를 관리한다. Yarn, Mesos등이 여기에 해당한다.
| desc | ex | |
| Cluster Manager | 클러스터 관리 | Yarn, Mesos |
| Cluster | 물리적 실행하는 '클러스터' | Hadoop |
이 개념을 알면 스파크가 어떻게 실행되는지 조금 명확해진다.
1. Spark Driver와 Spark Session
스파크는 논리적 실행 계획과 물리적인 실행 계획으로 나눌 수 있다. 논리적 실행 계획은 transformation, 코드가 유효한지를 보거나 테이블, 컬럼의 존재유무 등을 파악한다. 여기서 통과하면 물리적인 실행 계획을 세운다. 추가적인 최적화를 하는 것이다.
마치 Hive에서 논리적, 물리적 쿼리 최적화를 한 후에 하둡이나 스파크에서 실행하게 하는 것과 유사하게 보인다.
spark의 물리적 실행 계획은 Cluster에서 실행된다. Hadoop이 클러스터의 예시라고 볼 수 있다. 즉, 하둡에서 물리적인 실행을 한다는 거다.
spark driver가 하는 일을 정리해보자면 결국 spark session을 띄워서 논리적 실행 계획, 물리적 실행 계획을 세운다. 계획에 맞게 task들이 생성될 것이다. 이 task들을 어디에 할당해야 한다? cluster에 할당해야 한다. spark Driver가 Cluster Manager에게 요청한다. 그러면 CM이 요청받은 task들을 실행하기 위해 executor를 띄운다.
2. Cluster Manager (CM)
CM이 spark driver에게 요청을 받았다. 이제 task를 처리해야 한다. 이름 그대로 cluster의 매니저인 CM은 클러스터를 관리, 즉 리소스를 관리하는 역할이다. CM은 spark driver에게 받은 task 요청을 executor이 실행하게끔 한다. 그럼 executor process의 위치정보가 생길텐데, 이를 cluster driver process가 관리한다. executor process가 무슨 노드에서 실행 중인지, 몇 개의 코어나 메모리를 갖고있는지 등등의 정보를 cluster driver가 갖는다. (spark driver와 다른거다.)
cluster driver에서 task가 다 처리됐는지와 같은 상태를 체크한다. executor는 그럼 어디에 뜨는 걸까? driver worker node에 띄워진다. 클러스터 내 worker node에 executor가 뜬다. 보통 클러스터는 hadoop이니, hadoop 노드에 executor가 뜨는 것이다.
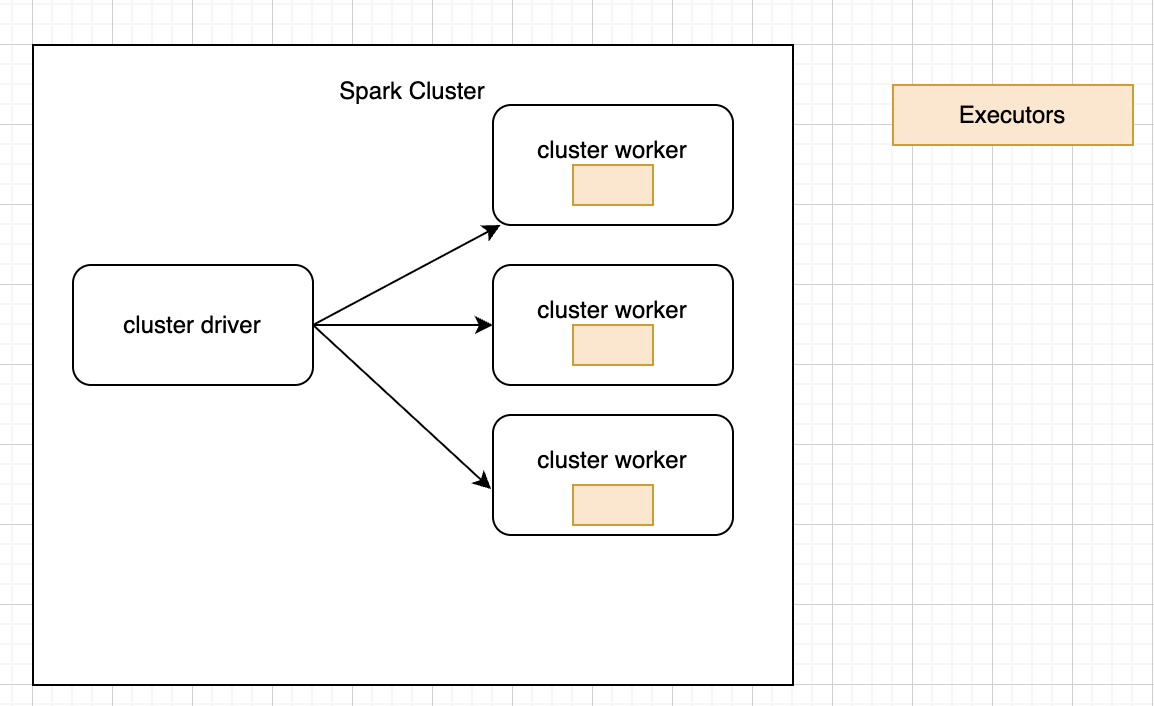
이 spark cluster를 관리하는게 CM이다.
큰 개념을 정리해보면 다음과 같다. 스파크가 실행되면
- spark driver의 spark session에서 프로세스를 핸들링하기 시작한다.
- spark session은 spark cluster와 통신을 하며 프로세스가 잘 돌고 있는지를 추적한다.
- cluster manager는 spark executor를 띄운다. executor는 태스크들을 할당받는다.
- executor는 할당받은 task들을 실행하고, 태스크 상태를 spark driver에게 공유한다.
- 모든 태스크가 종료되면 cluster manager가 executor를 종료시킨다. 끝!
3. Client VS Cluster Mode
그래서 클라이언트 모드와 클러스터 모드는 무엇이 다를까? 클라이언트 모드는 클러스터(ex. Hadoop)를 사용하지 않는 걸까? 아니다.
이 둘의 차이는 spark driver가 어디에 뜨는지다.
위에서 spark driver가 하는 일은 spark session을 띄우고 CM(ex. Yarn)과 통신을 하는거다. 이 driver는 어디에 뜰까? 모드에 따라서 달라진다.
- client mode: 로컬 머신에 스파크 driver가 뜬다.
- cluster mode: 클러스터의 Worker node에 위치한다. 즉, 하둡에 뜬다.
그렇기 때문에 스파크 모드에 따라서 driver의 세팅이 달라질 수 있다. 예를 들어서 드라이버 코어 수를 정할 때,
spark.driver.cores로컬머신에 뜬다면 로컬에서 가용가능한 코어 수를, cluster mode라면 하둡의 자원을 동적으로 할당할 수 있다.
드라이버에서 하는 일은 논리적 물리적 실행을 나누고 task를 요청하고 통신하는 거였다. 이때 필요한 가용 리소스를 생각하면 클러스터 모드를 주로 사용한다.
예를 들어, 클라이언트 모드로 실행 중에 spark driver OOM이 난다면 클러스터 모드로 바꾸는 걸 고려해야한다.
'머신러닝 > 기초 머신러닝' 카테고리의 다른 글
| 추천시스템 LinUCB 개념 파헤치기 (2) | 2025.10.11 |
|---|---|
| 딥러닝 모델 GPU 메모리 계산하기 (0) | 2025.09.21 |
| Positional Encoding 과 RoPE에 대하여 (0) | 2025.08.30 |
| transformer의 모든 것 (0) | 2024.04.28 |
| Attention 기초 수식 설명 (0) | 2023.12.17 |