딥러닝 모델 구조는 transformer의 등장 이전과 이후로 나뉜다고 해도 과언이 아닌 것 같다. RNN의 단점을 지우고 attention encoder와 decoder를 사용하는 구조로 자연어에서 변혁을 일으키며 나중에는 다른 도메인에서도 transformer를 안 쓰는 모델을 찾기가 힘들어졌다. MAMBA가 이제 판을 뒤집을지도 모르지만, 오늘은 transformer에 대해 기본을 탄탄히 잡아보자.
1. self attention
attention은 Query, Key, Value 3가지가 주어졌을 때 Query와 유사한 Key를 찾고, 이에 대한 Value 중 뭘 채택할지 retrival하는 과정이라 볼 수 있겠다. 단순하게 한국어 영여 번역 태스크를 수행하는 모델을 만든다고 가정할 때, Query는 입력된 영어 단어들, Key는 한국어 단어들, Value는 Key 각각 대응하는 어떤 값이 들어있다. Value값이 높을수록 해당 key와 query는 유사할 것이다. 수식은 아래와 같이 dot product로 이루어져 있다. attention의 결과 차원은 query의 dimension과 key의 dimension의 내적이 되는 것이다. 보다 자세한 내용은 이전에 작성한 Attention 기초 설명을 참고하면 좋을 듯 하다.

이제 self attention으로 들어가 보자. RNN의 구조를 단순하게 생각해 보면 input이 encoder로 들어갔다가 decoder로 나오는 구조이다. 즉 decoder가 encoder를 신경 써야 한다. 이러지 말고 encoder가 본인을 input으로 받는다면 어떨까? 바로 Query, Key, Value를 모두 본 input (x)로 받으면 말이다. 그러면 attention의 결과인 y의 차원은 input x와 똑같아진다. 만약 이를 다시 decoding을 한다고 하면 아래 수식의 x_i 자리에 yi_1을 넣으면 될 것이다.

여기서 해결되는 RNN의 단점 하나는 학습시 decoder 과정에서 bottleneck이 없어진다는 거다. 기존에는 sequential 하게 처리되었기 때문에 t번째 토큰은 t-1번째 토큰에 대한 연산이 끝날 때까지 기다려야 했다. 하지만 self attention은 모든 1~ t 번째 토큰을 다 같이 decoder에서 처리하기 때문에 병렬 연산이 가능해진다.
그리고 모든 토큰에 대해 보기 때문에 context 파악에 더욱 용이하다. RNN의 경우에는 t번째 토큰의 입장에서 t-1번째의 decoder 결과가 1~ t-1 번째까지의 문맥을 파악하고 있기를 '기대'했던 것의 업그레이드 버전인 것이다. 아래 예시를 보면 "it"이란 단어가 input context에 따라 중요도가 달라지는 것을 볼 수 있다.

2. Multi Head Attention (MHA)
attention 수행 결과를 head라고 부른다. attention을 여러 번 수행하여 concat하면 multi head attention이라고 한다. 이를 여러 번 하는 이유는 같은 Q, K, V 쌍이라도 다른 각도로 보면 similarity 차원에서 더 풍부해질 수 있기 때문이다.

multi head attention의 작동 방식은 pytorch의 multi head attention 구현체에 대한 글을 참고하면 좋겠다. 주관적인 의견으로는 Multi Query Attention(MQA)의 컨셉이 더 와닿는 편이다.
3. positional encoding
self attention 만으로는 충분하지 않다고 생각해 positional encoding이 등장했다. 어떤 점에서 self attention은 충분하지 않았을까? 바로 attention 연산은 토큰의 순서에 대해 크게 생각할 수 없는 구조이기 때문이다. 1 ~ t 번째 토큰이 input으로 들어갈 때 이에 대한 위치 정보를 추가해 줄 필요가 있는 것이다. 그래서 이번 개념에 'positional'이라는 단어가 들어간다.
positional embedding은 단어의 순서를 임베딩해주는 개념이다. 쉬운 예제로, 만약 "나는 집에 갔다." 라는 3개 단어가 있을 때 이를 길이가 3인 2진수로 임베딩하게 되면 001, 010, 011로 표현하게 될 것이다. 단어가 8개가 넘어가면 (2 **3) 길이 3의 이진수로는 더 이상 positional embedding을 할 수 없을 것이다.
이제부터 이 임베딩의 크기를 d라고 표현한다. 위 이진수와 같이 위치를 기억시킬 방법으로 sinusoidal basis을 통한 linear tranform을 쓰면 우리가 익히 아는 "positional embedding"이 완성된다. 아래 수식에서 p_i는 i번째 단어의 positional embedding을 나타내고 있다. C는 maximum sequence length를 의미한다.

이런 positional encoding(P)을 하면 좋은 점은 단어 간 상대적인 거리를 통해 지식을 뽑아낼 수 있다는 것이다. 아래 식을 보면 t번째 토큰의 P와 t+𝟇번째 토큰의 P의 차이가 w𝟇의 rotatory만큼 벌어져 있다는 뜻으로, 실제 t와 t+𝟇번째 토큰이 가깝게 위치한다면 임베딩 또한 유사하게 형성될 것이다.

참고로 이 부분은 llama2로 오면서부터 rotational positional encoding으로 바뀌는 등 변주가 생기고 있다.
positional embedding을 기존 임베딩에 더해준다면, transformer에 필요한 임베딩은 끝이다.
4. 전체적인 구조
transformer의 구조는 크게 encoder와 decoder 부분으로 나뉜다.
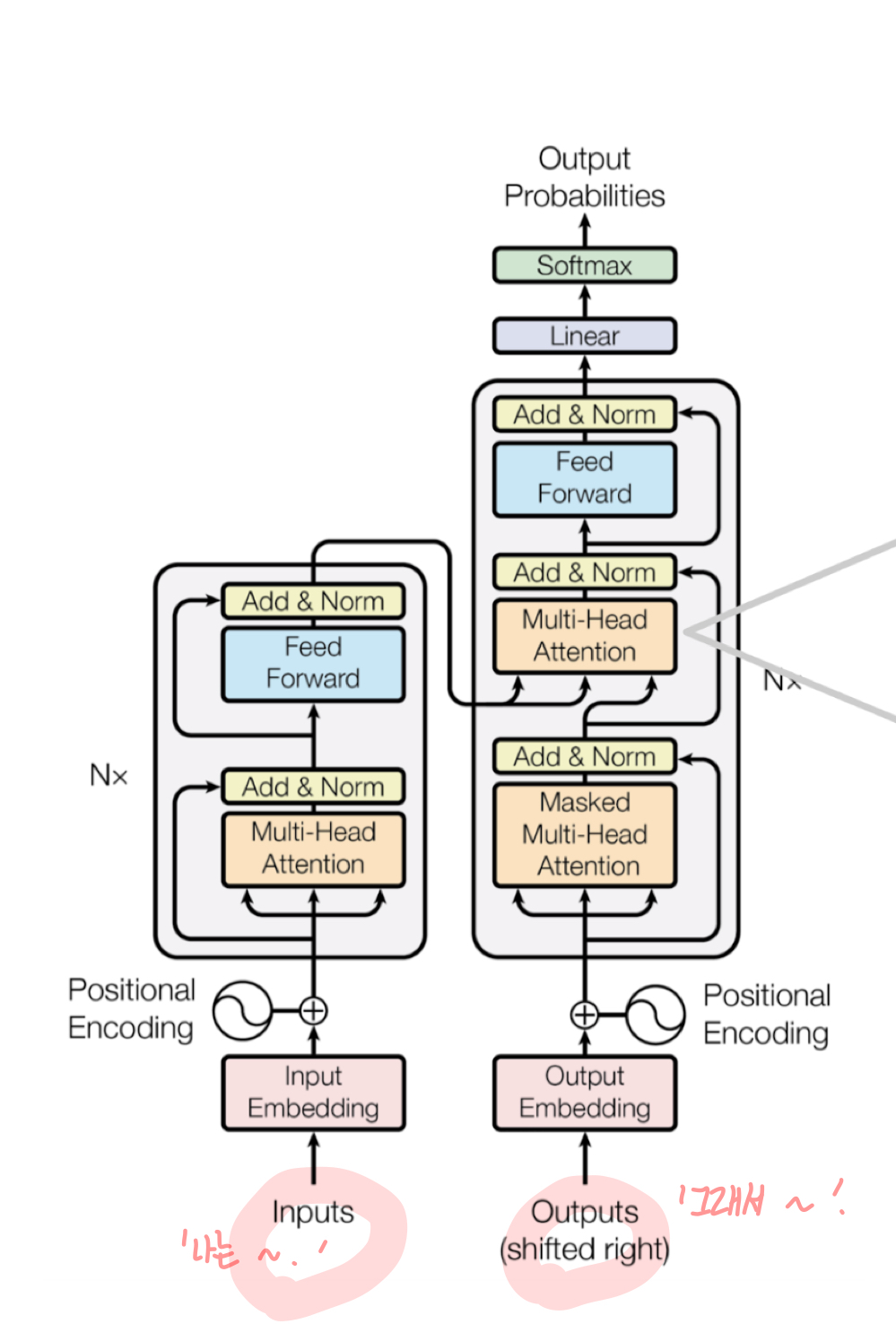
1. Encoder : input이 주어졌을 때, input의 임베딩과 positional embedding을 더한 값을 토대로 attention 연산을 수행한다.
2. Decoder: output에 대해서도 똑같이 진행한다. 이후 output의 attention결과를 Query, input의 attention 결과(encode의 결과)를 Key, Value로 받는 attention을 한 번 더 수행한다.
하나의 학습 예시를 들어보겠다. '나는 밥을 먹었다. 그래서 나는 배가 부르다.'라는 문장을 학습할 때에 앞 문장을 decoder의 Input, 뒷 문장을 encoder의 intput이라고 가정해 보자. 첫 문장이 왔을 때 그다음 문장을 생성하는 generation task를 학습한다고 가정하는 것이다. 이때 Encoder에서는 '그래서 나는 배가 부르다.'에 대한 정보를 담는 self attention을 수행한다.
이후 Decoder에선 '나는 밥을 먹었다.'가 input으로 들어가게 된다. decoder의 첫 MHA에선 encoder와 유사하게, '나는 밥을 먹었다.'에 대한 정보를 담는 self attention이 진행된다. 이후 한 번 더 attention을 수행하게 되는데, 이때의 Key, Value 값은 첫번째 문장의 정보를 가져온다. '나는 밥을 먹었다.' 뒤에 어떤 문장이 오게 될지 생성하는 task라 이전 문장을 참고하는 것이 자연스러워 보인다. 따라서 decoder 단에서 '나는 밥을 먹었다.'에 대한 mask된 attention을 query로 했을 때, 이와 가장 유사할 다음 문장에 대한 key값을 찾고자 하는 것이다.
transformer 구조에 대해 더 깊은 코드 이해는 transformer 구현 코드로 알아보기를 참고하면 좋을 듯하다.
5. transformer vs CNN vs RNN
CNN, RNN과 transformer는 표현력에서 분명한 차이가 있다. 아래 그림을 보자. CNN은 kernel이 3일 때를 가정한 듯하다. 한 depth당 3개의 length에 해당하는 정보를 저장하고 있다. RNN은 한 번에 하나의 input을 저장하고, 이를 오른쪽으로 흘려주는 것을 sequential 하게 진행한다. 마지막으로 self attention에서는 한 번에 모든 input들을 통으로 연산하는 것을 볼 수 있다.

다음은 연산량이다. 연산량에 대해서는 아래 표와 같이 나타낼 수 있다. CNN은 kernel dim에 따라 시간복잡도가 늘어날 수밖에 없다. self attention의 시간복잡도는 RNN 에 비해서 hidden size d 보다 sequence length n에 더 민감하다. 그럴 수밖에 없는 게, self attention은 key, query, value 다 (n, d)의 matrix에 대한 내적이기 때문이다.

오늘은 transformer에 대해 하나부터 열까지 다뤄보았다. 기존에 중요한 개념들은 따로 구현하거나 코드를 설명한 적이 있었는데, 해당 부분을 최대한 쉬운 버전으로 설명하고자 노력했다..!
reference: 머피의 머신러닝 1.
'머신러닝 > 아맞다' 카테고리의 다른 글
| Attention 기초 수식 설명 (0) | 2023.12.17 |
|---|---|
| PCA의 완벽한 이론 설명 (0) | 2023.10.29 |
| Mutual Information 파헤치기 (0) | 2023.10.14 |
| 엔트로피와 KL Divergence (0) | 2023.10.08 |
| linear regression의 완벽한 기초 수식 (0) | 2023.09.30 |