2021. 9. 20. 22:43ㆍ논문리뷰
OCR에 관한 SOTA를 찾던 중 읽은 논문이다. 2017년 논문인데 소타라는게 조금 신기하긴 했는데 (4년 전 논문인 건데!) , 기본적인 구조는
CNN + RNN + Attention
이다.
논문 링크는 다음과 같다: https://arxiv.org/abs/1704.03549
Attention-based Extraction of Structured Information from Street View Imagery
We present a neural network model - based on CNNs, RNNs and a novel attention mechanism - which achieves 84.2% accuracy on the challenging French Street Name Signs (FSNS) dataset, significantly outperforming the previous state of the art (Smith'16), which
arxiv.org
1. Introduction
딥러닝으로 OCR을 하기 위한 방법론을 제시하고, 이전 모델들과의 비교 실험 등을 진행했다. 이는 주어진 이미지에서 텍스트를 문자화 하는 것보다는, 유용한 정보의 잔재를 추출하는 방식을 제안한다. 주의 깊게 볼 내용은 다음과 같다.
- 해당 논문의 이전 SOTA는 FSNS으로, data augmentation + LSTM 모델이며 CTC loss ( ConnectionistTemporal Classification loss)을 사용했다. 해당 논문에서는 CTC loss를 쓰지 않는다.
- inception-v3, incetion-v2, inception-resnet-v2를 CNN 모델로서 각각 실험한다.
- CNN 층의 깊이가 일정 이상 깊어지면, 정확도가 오히려 하락한다.
2. Methods
논문의 모델은 CNN + RNN + Attention으로 이루어져 있다. CNN을 통과하면서 feature map을 생성하고, feature map으로 attention계수를 구해 RNN에 활용하는 순서로 진행이 된다.
- CNN : feature map 생성
- Spatial Attention

6번 수식은 어텐션을 구하는 방법이다. V는 벡터, W_s s는 이미지 내 어디를 봐야 하는지, W_f f는 시간 변수의 offset이다. 이렇게 6번에서 softmax를 거치면 attention 계수를 구할 수 있다. tanh 함수 내에 있는 식에서 공간적 좌표를 생각하는 'location aware'를 하고 싶다면, 식은 다음과 같이 변할 수 있다.

뒤에 e_i와 e_j에 대한 식이 붙은 것을 알 수 있다. 좌표를 원핫 인코딩한 것인데, 이를 공간에 대한 bias term으로 볼 수도 있다. 이는 이전 연구에 소개된 location-aware attention과는 다른데, 이거는 W가 convolution 필터였고, tanh내에 위치 좌표를 원핫으로 주지도 않았다.
- RNN
용어 정리를 하면 다음과 같다.
- s : hidden state
- u : weighted combination of features
- x_hat : total input
- (o, s) = RNN( x_hat , s(t-1))
- o_hat : softmax(W * o + W * u)
여기서 u의 공식은 아래와 같다. 위에서 구한 어텐션 계수와 CNN 커널을 통과한 feature map의 곱이다.

x_hat은 LSTM에서 새로운 cell state라고 생각하면 된다. 아래 수식을 보면, 이전 글자의 인덱스(a)와 이전 글자에서 구했던 feature map과 attention의 계수(b)를 더해줌을 알 수 있다.

논문에서는 RNN이라 나오지만, 뒤에 실험 부분을 보면 LSTM을 썼음을 추정할 수 있다.
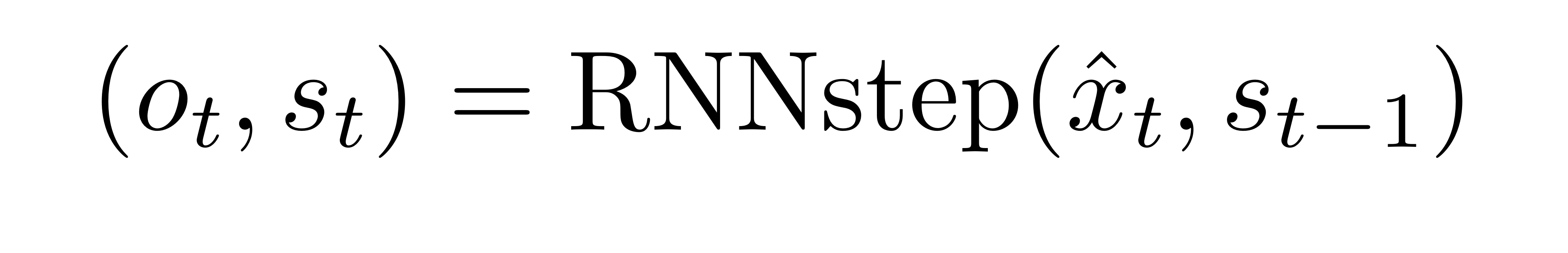
이후 수식은 다음과 같다. 소프트맥스 값을 구한 후, 글자의 인덱스를 반환한다.


3. Training
- loss : (penalized) maximumlikelihood (-> 왜 penalized인지는 모르겠다. 논문에 자세히는 안 나와있음.)
- optimizer : SGD(stochastic gradient descent)
- learning rate : 1e-2, decay factor 0.1
- image crop : 0.8 to 1.2. 그 후에 원사이즈로 resize 함.
- label smoothing: 0.9
- LSTM unit size : 256
- batch size : 32
메모리 연산 상 GPU를 32개나 썼다고 한다. 32개로 10시간 걸렸다고 하니, 처음부터 구현해서 실험, 학습하면 얼마나 걸릴까...ㅠㅅㅠ
4. 추가
- 데이터셋은 FSNS ( 길거리 표지판 오픈 데이터셋)과 자체 제작 데이터를 사용했다고 한다. 조금주의 깊게 봐야 할 부분은 CNN depth에 따른 정확도 실험이다.
- inception-V2로 실험했을 때는 depth 24, inception-V3는 depth 36일 때 가장 좋은 퍼포먼스를 보였다. 나중에 해당 모델을 pretrained로 사용할 때 참고하자.
- 모델의 행동을 이미지로 visualization을 했는데, 이때 이미지를 약 16개 버전으로 augmentation 한 것으로 추측할 수 있다. 가우시안 노이즈를 추가한 후(그랬을 때 1개 원본 이미지 당 16개 이미지가 나왔다는 듯)에 해당 이미지들의 노이즈 버전을 평균 냈다고 한다. 참고) 아래 예시 사진에서는 R 다음 u, e에서는 attention map이 없는데, 그 이유는 RUE라는 거리 이름이 많아서 R에서 쉽게 뒤 단어들을 추측했기 때문이라고 한다.

오늘은 OCR의 SOTA논문을 탐구해 보았다. 논문에서는 비슷한 단어들이 추측을 틀리는 경우를 보여주었는데, 그 예시로는 e, e` 이 있었다. 우리나라로 치면 ㅇ, ㅎ이 여기에 해당될 수 있을 것 같다. 저자가 tensorflow로 코드를 공개해놨으니, 필요하면 pytorch로 바꿔보면서 코드 공부를 해도 좋을 듯하다. 수식과 하이퍼 파라미터를 꽤나 자세하게 논문에 기재해주셨다.
한글 OCR을 어떤 식으로 발전시키면 좋을지 잘 생각해보자.
'논문리뷰' 카테고리의 다른 글
| [Paper] DPO 논문 리뷰 (1) | 2023.11.13 |
|---|---|
| Exploring Simple Siamese Representation Learning 논문 간단 리뷰 (0) | 2022.05.02 |
| [Paper] Phydnet 리뷰 (0) | 2021.09.05 |
| [Paper] Recurrent Attention Model 논문 리뷰 - 2 (0) | 2021.09.05 |
| [Paper] Recurrent Attention Model 논문 리뷰 - 1 (0) | 2021.09.05 |